In this paper, we propose MoDGS, a new pipeline to render novel-view images in dynamic scenes using only casually captured monocular videos. Previous monocular dynamic NeRF or Gaussian Splatting methods strongly rely on the rapid movement of input cameras to construct multiview consistency but fail to reconstruct dynamic scenes on casually captured input videos whose cameras are static or move slowly.
To address this challenging task, MoDGS adopts recent single-view depth estimation methods to guide the learning of the dynamic scene. Then, a novel 3D-aware initialization method is proposed to learn a reasonable deformation field and a new robust depth loss is proposed to guide the learning of dynamic scene geometry. Comprehensive experiments demonstrate that MoDGS is able to render high-quality novel view images of dynamic scenes from just a casually captured monocular video, which outperforms baseline methods by a significant margin.
Here we display side-by-side videos comparing our method to the most recent Gaussian Methods.
Select a scene and a baseline method below:

Fig 1.Overview. Given a casually captured monocular video of a dynamic scene, MoDGS represents the dynamic scene with a set of Gaussians in a canonical space and a deformation field represented by an MLP network T. To render an image at a specific timestep 𝑡, we deform all the Gaussians by T𝑡 and then use the splatting technique to render images and depth maps. While in training MoDGS, we use a single-view depth estimator GeoWizard [Fu et al. 2024] to estimate a depth map for every frame and compute the rendering loss and an ordinal depth loss to learn MoDGS.
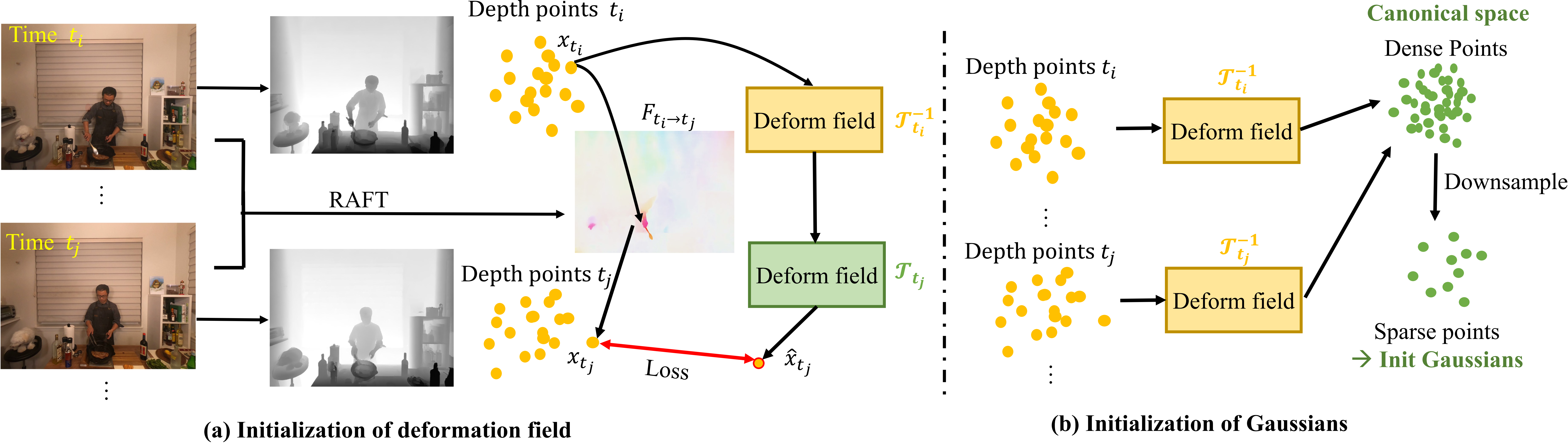
Fig 2.(a) Initialization of the deformation field. We first lift the depth maps and a 2D flow to a 3D flow and train the deformation field for initialization. (b) Initialization of Gaussians in the canonical space. We use the initialized deformation field to deform all the depth points to the canonical space and downsample these depth points to initialize Gaussians.
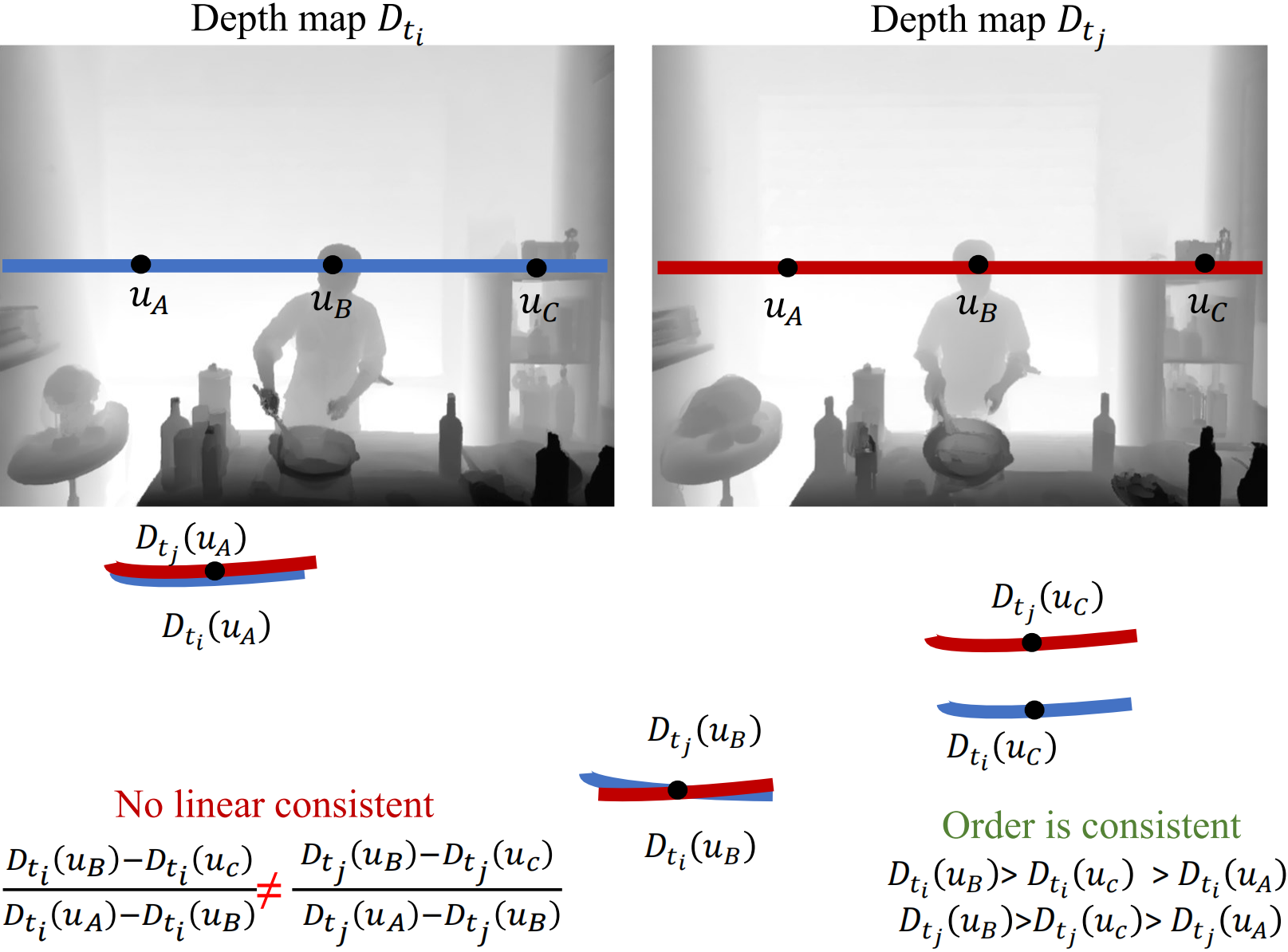
Fig 3. We show the estimated single-view depth maps at two different timesteps 𝐷𝑡𝑖 and 𝐷𝑡𝑗 after normalization to the same scale. Since the single-view depth estimator is not accurate enough, the depth maps are not linear related so the scale normalization does not perfectly align them. However, the order of depth values on three corresponding pixels is stable for these two depth maps, which motivates us to propose an ordinal depth loss for supervision.
Please See our video results above ,our rendered depth videos are more consistent and stable than the inputs.